Fui a Google Cloud Next y Volví Obsesionada con la Observabilidad de la IA 🔗
El ejemplo completo del que hablo en este post está en el repositorio dash0-examples. Este post explica por qué existe y qué obtienes cuando lo ejecutas.
Volví de Google Cloud Next hace una semana y, sinceramente, todavía lo estoy procesando. Lo pasé increíble. Fue mi primera conferencia de Google y superó todas mis expectativas. Además de estar en el stand haciendo demos en inglés y en portugués (¡sí!) recorrí el expo hall y el único tema que surgió en todas partes, en cada sesión, cada stand, cada conversación de pasillo, fue agentes. Agentes de IA.

Sistemas de IA tomando decisiones, llamando herramientas, lanzando otros agentes, escribiendo código, desplegando cosas. Fui esperando mucho contenido sobre infraestructura cloud y volví con la cabeza llena de pipelines agénticos.
Y en algún momento del segundo día, un pensamiento se me coló que no podía sacudir:
Si esto empieza a comportarse raro a las 3am (respuestas lentas, outputs incorrectos, costos desbocados), ¿por dónde empiezas a buscar?
Esa pregunta me llevó por un camino de búsqueda, porque necesitas poder ver qué hay adentro. No solo “¿está arriba o abajo?” Realmente ver qué está pasando dentro de la IA.
Así que construí una demo pequeña para entender cómo se ve eso en la práctica. Empecé por la capa de inferencia, específicamente vLLM, que es lo que muchos equipos usan para hacer self-hosting de modelos de IA (¡y es Open Source!). Esto es lo que aprendí.
Primero: ¿qué es vLLM y por qué importa? 🔗
Si escuchaste hablar de ChatGPT pero no de vLLM, la versión rápida es esta: ChatGPT es un producto. Por debajo hay un modelo (el cerebro real de la IA) y un servidor que maneja todas las solicitudes, como recibir texto, pasarlo por el modelo y devolver una respuesta.
vLLM es uno de esos servidores. Es lo que muchos equipos usan cuando quieren alojar su propio modelo de IA en lugar de pagar por la API de otra persona. Es rápido, es open source y se ha convertido en el estándar para el serving de IA self-hosted.

La parte interesante para nosotros es que vLLM tiene observabilidad incorporada. Puedes configurarlo para que reporte automáticamente lo que está haciendo, y esos datos fluyen hacia tus herramientas de monitoreo con casi nada de código extra. Digo “casi” porque sí necesitas pasar un flag y configurar un collector, pero eso lo vemos más adelante. Sin código de instrumentación personalizado en tu aplicación.
¿Qué significa “observabilidad” para una IA? 🔗
Entiendo mejor las cosas con analogías, así que imagina que tu modelo de IA es una cocina de restaurante. Los clientes (usuarios) mandan pedidos (solicitudes). La cocina (el servidor de IA) prepara la comida (genera respuestas) y la devuelve.
Ahora algo sale mal. Los pedidos están tardando demasiado. ¿Qué haces?
Sin observabilidad, estás parado afuera de la cocina sin ventanas. Sabes que los pedidos están lentos. Eso es todo.
Con observabilidad, puedes ver:
- Cuántos pedidos están esperando para empezar
- Qué pedidos se están cocinando ahora mismo
- Qué paso está tardando más (¿es la preparación o la cocción?)
- Qué tan lleno está el espacio de trabajo de la cocina (si se desborda, los pedidos se preemptan y tienen que empezar de cero)
Los servidores web normales tienen versiones de todos estos problemas. Pero los servidores de IA tienen su propia versión de cada uno, y las señales que necesitas monitorear son completamente distintas. Por eso vLLM trae su propia capa de observabilidad.
Los dos tipos de datos que obtienes 🔗
Trazas: GPS tracking de tu solicitud 🔗
Una traza es un registro de todo lo que le pasó a una solicitud. Cada paso, en orden, con timestamps.
Cuando tu app manda una pregunta a la IA:
- Tu app recibe la solicitud
- Tu app busca contexto (si usas RAG)
- Tu app llama al modelo de IA
- El servidor de IA agenda la solicitud
- La IA genera la respuesta, token por token
- La respuesta vuelve
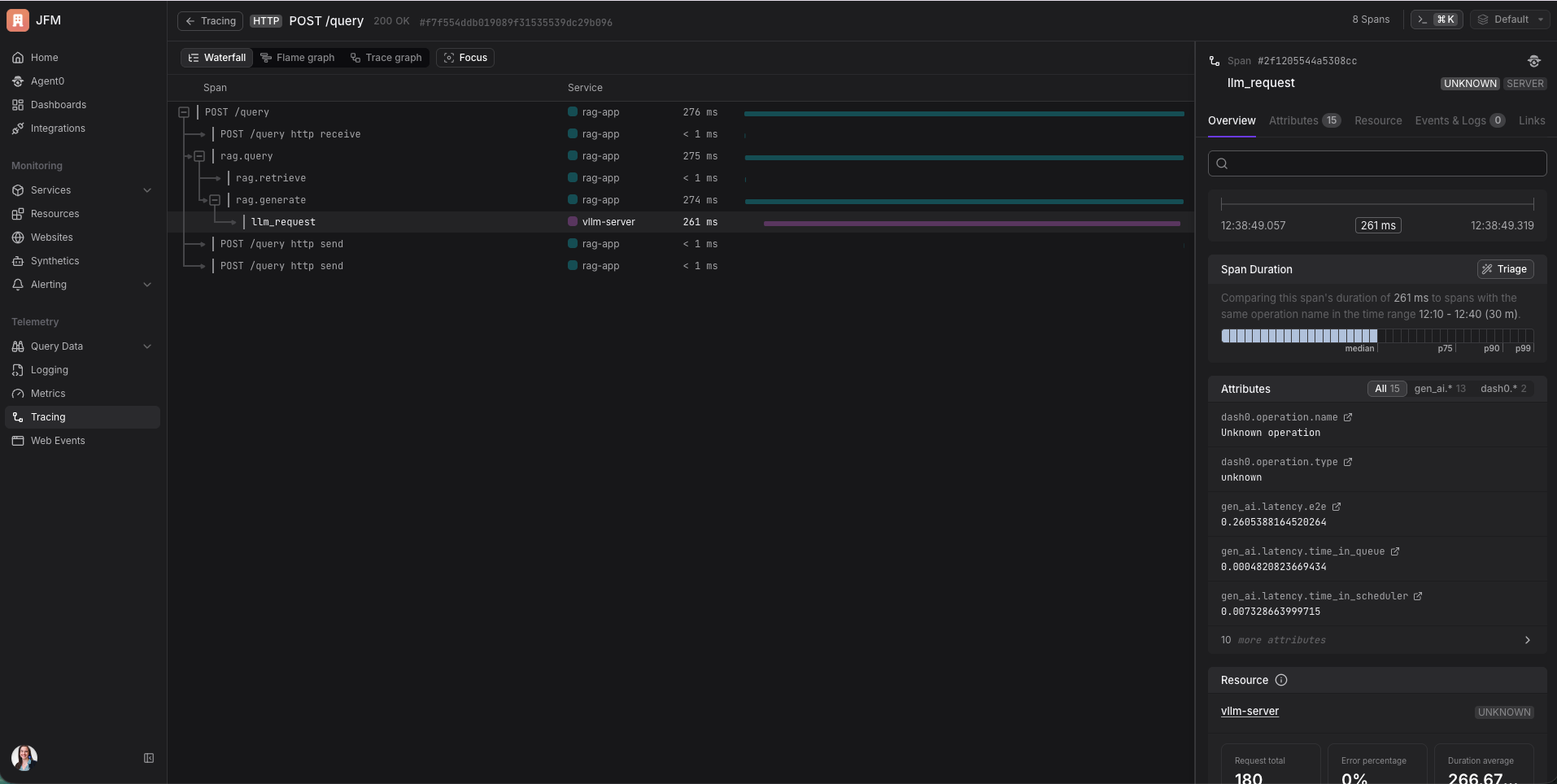
Una traza captura todo eso y te muestra exactamente dónde se fue el tiempo. ¿La IA fue lenta porque el servidor estaba saturado con otras solicitudes? ¿Fue lenta porque el prompt era muy largo? La traza te lo dice.
Si lo configuras bien, obtienes una traza continua que cruza múltiples servicios. Mi app RAG y el servidor vLLM son dos procesos separados, pero en Dash0 los veo como un waterfall conectado. “Mi app tardó 85ms en buscar documentos y 360ms esperando a la IA.” En una sola vista. Sin ningún plumbing extra más allá de inyectar un header. Es hermoso verlo.
Métricas: el dashboard en la pared de tu cocina 🔗
Las métricas son números que se actualizan con el tiempo. Menos detalle que las trazas, pero más fáciles de monitorear continuamente y de configurar alertas.
Las que realmente importan:
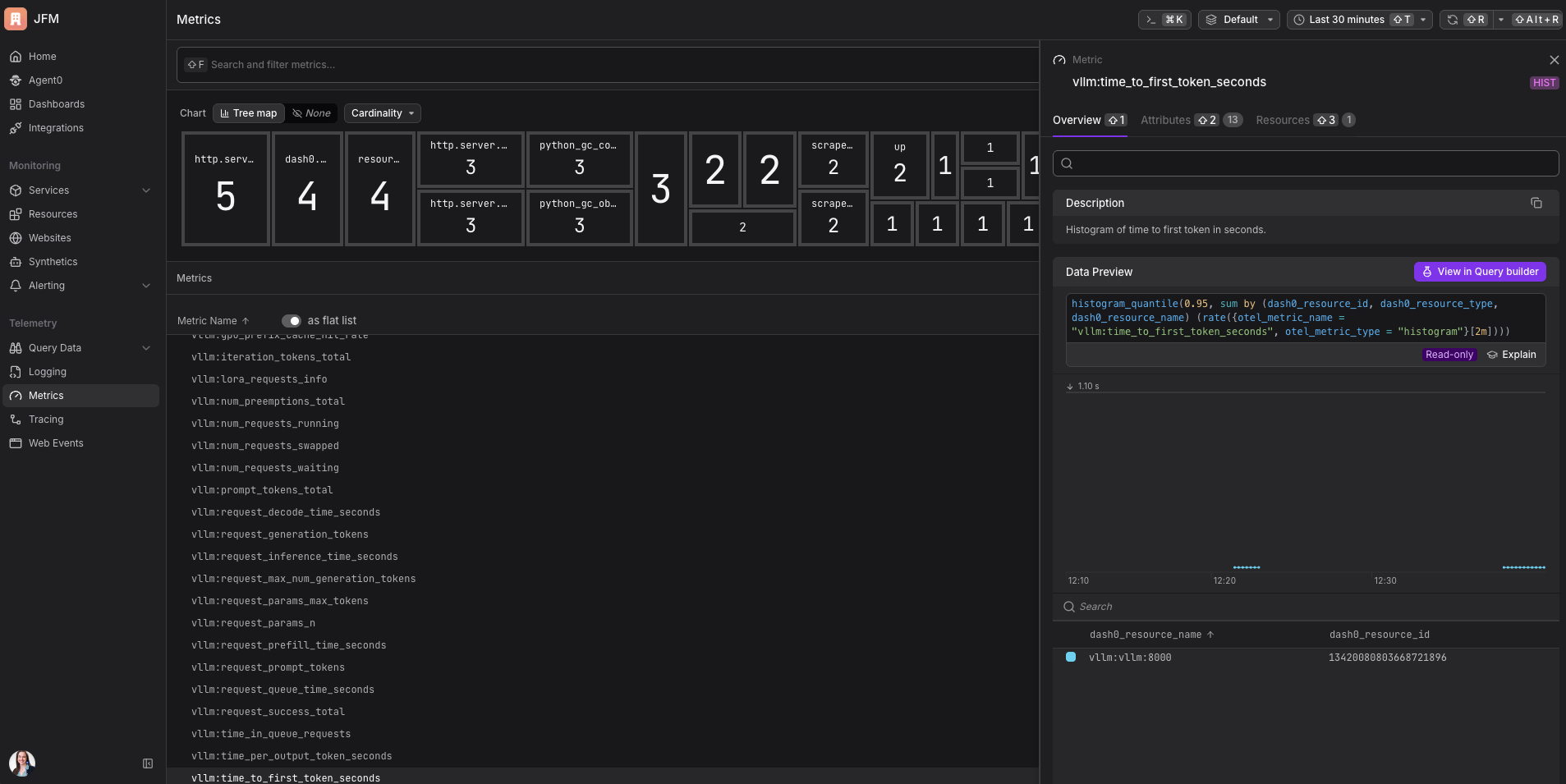
Tiempo hasta el primer token. Cuánto tarda el usuario en ver la primera palabra de la respuesta. Para cualquier cosa con una UI de streaming donde el texto aparece mientras se genera, esto es lo que determina si el producto se siente rápido. No tenía idea de que esto se medía por separado de la latencia total antes de profundizar en vLLM. Tiene todo el sentido en retrospectiva.
Uso del caché de GPU. Este necesita su propia analogía. La GPU tiene un tipo especial de memoria de trabajo llamado KV cache. Piénsalo como el cuaderno de notas de un chef: cuando el chef está a mitad de una receta compleja, anota cosas para no perder el hilo. La IA hace lo mismo durante la generación. Cuando el cuaderno se llena, el chef tiene que borrar las notas de otra persona para hacer espacio, lo que significa que ese pedido tiene que empezar desde cero. En vLLM esto se llama preemption, y causa picos de latencia repentinos que aparecen como solicitudes lentas en lugar de errores. La métrica de uso del caché de GPU te dice qué tan lleno está ese cuaderno antes de que empiecen a borrarse cosas. Jamás hubiera pensado en monitorear esta métrica antes de este proyecto. Ahora es lo primero que reviso.
Solicitudes en espera. Cuántas solicitudes están en cola pero aún no se están procesando. Esto sube antes de que la latencia explote. Es un indicador adelantado, exactamente el tipo de señal que es útil para la planificación de capacidad.
Tokens por segundo. El throughput de tu setup. Útil para saber si estás sacándole provecho a tu hardware.
Cómo fluyen los datos 🔗
Aquí está la arquitectura en términos simples:
Tu app
│
│ manda una pregunta
▼
vLLM (el servidor de IA)
│
├── envía datos de trazas automáticamente → OTel Collector
└── expone métricas en /metrics → OTel Collector las scrapea
│
│ reenvía todo
▼
Dash0
(donde lo ves todo)
El OTel Collector es un intermediario que recibe datos de múltiples fuentes y los reenvía a tu backend de observabilidad. Piénsalo como la sala de correo del edificio: todo pasa por ahí antes de llegar a su destino final. También maneja cosas como batching, reintentos y enriquecer la telemetría con contexto extra, por eso conviene tenerlo en el pipeline en lugar de enviar directamente.
OpenTelemetry (OTel) es el formato estándar que usa todo esto. Es vendor-neutral, lo que significa que el mismo setup funciona tanto si envías a Dash0, Grafana, o cualquier otra herramienta que hable OTel. Yo uso Dash0 porque es donde trabajo, jaja. Ver que las métricas y trazas de vLLM aparecían en la misma vista sin escribir ningún código de pegamento fue el momento en que realmente lo entendí. Si tienes curiosidad por qué importa ser OTel-native, ese post lo explica bien.
Cómo configurarlo 🔗
El setup completo está en el repositorio dash0-examples.
Lo que necesitas:
- Docker y Docker Compose
- Una máquina con GPU NVIDIA
- Una cuenta de Dash0 (basada en consumo, gratis por 14 días)
Lo de la GPU. Esto me confundió. Asumí que podía correr la demo en mi Mac, quizás lento. Para nada. La imagen Docker de vLLM está compilada específicamente para NVIDIA CUDA. No es una situación de “corre más lento sin GPU”, simplemente no corre. Pasé una cantidad vergonzosa de tiempo intentando que funcionara antes de aceptar la realidad y levantar una instancia en Google Cloud.
Para las pruebas usé una n1-standard-4 con una GPU T4 en Google Cloud (aproximadamente $0.50/hora). Más que suficiente para el modelo pequeño de esta demo. Algo importante que revisar antes de intentarlo: Google Cloud limita cuántas GPUs puedes usar por defecto, a veces a cero. Ve a IAM & Admin → Cuotas en la consola de Google Cloud, busca NVIDIA_T4_GPUS, selecciona tu región y solicita un aumento. Generalmente se aprueba en pocas horas. Yo no sabía que esto existía hasta que choqué con el límite y recibí un error críptico en lugar de un mensaje útil.
Lo bueno de Google Cloud: puedes conectarte a tu instancia con gcloud compute ssh en lugar de gestionar archivos .pem. Sin chmod 400, sin “¿dónde puse esa clave?":
gcloud compute ssh nombre-de-tu-instancia --zone=us-central1-a
Y cuando termines de usarlo, ¡acuérdate de detener la instancia! De lo contrario te llegará una factura enorme a fin de mes.
La espera al cargar el modelo. La primera vez que corres docker compose up, vLLM descarga los pesos del modelo y los carga en la memoria de la GPU. Esto tarda entre 2 y 5 minutos. El stack parece congelado. No está congelado. Espera esta línea antes de mandar cualquier solicitud:
INFO: Application startup complete.
En mi primer intento mandé solicitudes antes de ver esta línea. Me confundí mucho sobre por qué nada funcionaba. Ahora tú ya lo sabes.
Pasos:
-
Clona el repositorio:
git clone https://github.com/dash0hq/dash0-examples.git cd dash0-examples/vllm -
Agrega tus credenciales de Dash0 al archivo
.enven la raíz del repositorio. Las encuentras en la página de configuración de tu cuenta.DASH0_AUTH_TOKEN=tu_token_aqui DASH0_DATASET=default DASH0_ENDPOINT_OTLP_GRPC_HOSTNAME=ingress.us-west-2.aws.dash0.com DASH0_ENDPOINT_OTLP_GRPC_PORT=4317 -
Inicia todo (requiere GPU NVIDIA, o consulta la sección de configuración de vLLM en el análisis técnico detallado para saber cómo correrlo en CPU):
docker compose up --build -
Espera a que cargue el modelo. Busca
Application startup complete.en los logs. -
Manda una solicitud de prueba:
python scripts/send-request.py
Luego ve a Dash0. Los datos deberían estar fluyendo.
Lo que realmente ves 🔗
Esta es la parte que hizo que todo valiera la pena.
En las trazas, cada solicitud aparece como un árbol conectado. Puedes ver el flujo completo desde que tu app recibe la solicitud hasta que la IA termina de generar, con tiempos en cada paso. El span de la IA tiene atributos que muestran cuántos tokens había en el prompt, cuántos se generaron, y cómo se distribuye la latencia dentro de vLLM (tiempo esperando en cola, tiempo en prefill, tiempo en decode).
En las métricas, obtienes una vista en tiempo real de la salud del servidor de IA. ¿Se está llenando el caché de GPU? ¿Está formándose una cola? La métrica en la que pondría una alerta primero: tiempo hasta el primer token en el percentil 95. Si eso sube, los usuarios lo están sintiendo antes de que cualquier otra cosa se rompa.
Por qué esto importa más allá de la demo 🔗
Esto es en lo que no dejé de pensar en el vuelo de regreso de Google Cloud Next.
Los agentes que todos demostraban no son modelos únicos. Son pipelines con un orquestador que llama herramientas, busca datos, lanza sub-agentes, llama a un modelo, procesa el resultado, vuelve a llamar al modelo. Cada paso puede fallar. Cada paso tiene latencia. Sin instrumentación estás depurando ese sistema completamente a ciegas.
Pero si cada componente propaga el contexto de traza a través de sus llamadas, y si la capa de IA emite sus propios spans, terminas con una traza continua por interacción de usuario que cubre toda la ejecución. Puedes ver dónde fue el tiempo, qué llamadas a herramientas fueron lentas, y si el cuello de botella fue el modelo o la infraestructura que lo rodea.
Eso es lo que quería poder hacer. Esta demo es el primer paso. Mucha gente en la comunidad cloud-native está trabajando en este mismo problema ahora mismo. No tengo todas las respuestas todavía, pero creo que construir y compartir sobre la marcha es cómo lo vamos a resolver juntos.
Si quieres ver cómo se ve la observabilidad agéntica una vez que la infraestructura está en su lugar, Dash0 tiene una guía práctica que vale la pena leer junto a este post.
Pruébalo tú mismo 🔗
El ejemplo completo está en dash0-examples/vllm. Clónalo, apúntalo a tu modelo y ve cómo tu capa de inferencia se vuelve observable en minutos. Comienza tu prueba gratuita de Dash0 si todavía no tienes una cuenta.
Si lo intentas y algo no te queda claro, encuéntrame en LinkedIn. Y si ya estás pensando en cómo extender esto a pipelines de agentes completos, yo también. Eso es lo que estoy trabajando a continuación. 💙