Je suis allée à Google Cloud Next et je suis revenue obsédée par l’observabilité de l’IA 🔗
L’exemple complet dont je parle dans ce post se trouve dans le dépôt dash0-examples. Ce post explique pourquoi il existe et ce que tu obtiens en l’exécutant.
Je suis rentrée de Google Cloud Next il y a une semaine et honnêtement, je suis encore en train de digérer tout ça. J’ai passé un moment incroyable. C’était ma première conférence Google et elle a largement dépassé mes attentes. En plus du temps passé au stand à faire des démos en anglais et en portugais (oui !) j’ai parcouru le hall d’exposition et le seul sujet qui revenait partout, dans chaque session, chaque stand, chaque conversation de couloir, c’était les agents. Les agents IA.

Des systèmes IA qui prennent des décisions, appellent des outils, lancent d’autres agents, écrivent du code, déploient des choses. J’y allais en m’attendant à beaucoup de contenu sur l’infrastructure cloud et je suis repartie avec la tête pleine de pipelines agentiques.
Et quelque part au cours du deuxième jour, une pensée s’est insinuée que je ne pouvais pas chasser:
Si ce truc commence à se comporter bizarrement à 3h du matin (réponses lentes, outputs incorrects, coûts qui s’envolent), par où tu commences à chercher ?
Cette question m’a entraînée dans un terrier de lapin parce qu’il faut pouvoir voir ce qu’il y a à l’intérieur. Pas juste “est-ce que c’est en ligne ou pas.” Vraiment voir ce qui se passe à l’intérieur de l’IA.
Alors j’ai construit une petite démo pour comprendre à quoi ça ressemble en pratique. J’ai commencé par la couche d’inférence, spécifiquement vLLM, qui est ce que beaucoup d’équipes utilisent pour héberger leurs propres modèles IA (et c’est Open Source !). Voici ce que j’ai appris.
D’abord : c’est quoi vLLM et pourquoi c’est important ? 🔗
Si tu as entendu parler de ChatGPT mais pas de vLLM, voici la version courte: ChatGPT est un produit. Sous le capot, il y a un modèle (le vrai cerveau IA) et un serveur qui gère toutes les requêtes, comme recevoir du texte, le faire passer par le modèle et retourner une réponse.
vLLM est l’un de ces serveurs. C’est ce que beaucoup d’équipes utilisent quand elles veulent héberger leur propre modèle IA plutôt que de payer pour l’API de quelqu’un d’autre. C’est rapide, c’est open source, et c’est devenu un peu le standard pour le serving IA en self-hosted.

La partie intéressante pour nous: vLLM a l’observabilité intégrée. Tu peux le configurer pour qu’il rapporte automatiquement ce qu’il fait, et ces données arrivent dans tes outils de monitoring avec presque aucun code supplémentaire. Je dis “presque” parce qu’il faut bien passer un flag et configurer un collector, j’y reviendrai. Mais pas de code d’instrumentation personnalisé dans ton application.
Qu’est-ce que “l’observabilité” veut dire pour une IA ? 🔗
Je comprends mieux les choses avec des analogies, alors imagine que ton modèle IA est une cuisine de restaurant. Les clients (utilisateurs) passent des commandes (requêtes). La cuisine (le serveur IA) prépare les plats (génère des réponses) et les renvoie.
Maintenant quelque chose se passe mal. Les commandes prennent une éternité. Qu’est-ce que tu fais ?
Sans observabilité, tu es debout à l’extérieur de la cuisine sans fenêtres. Tu sais que les commandes sont lentes. C’est tout.
Avec l’observabilité, tu peux voir:
- Combien de commandes attendent pour démarrer
- Quelles commandes sont en cours de préparation
- Quelle étape prend le plus de temps (est-ce la mise en place ou la cuisson ?)
- À quel point l’espace de travail de la cuisine est rempli (s’il déborde, les commandes sont interrompues et doivent repartir de zéro)
Les serveurs web classiques ont des versions de tous ces problèmes. Mais les serveurs IA ont leur propre variante de chacun, et les signaux à surveiller sont complètement différents. C’est pourquoi vLLM embarque sa propre couche d’observabilité.
Les deux types de données que tu obtiens 🔗
Les traces : le GPS de ta requête 🔗
Une trace est l’enregistrement de tout ce qui est arrivé à une requête. Chaque étape, dans l’ordre, avec des timestamps.
Quand ton app envoie une question à l’IA:
- Ton app reçoit la requête
- Ton app récupère du contexte (si tu utilises RAG)
- Ton app appelle le modèle IA
- Le serveur IA programme la requête
- L’IA génère la réponse, token par token
- La réponse revient
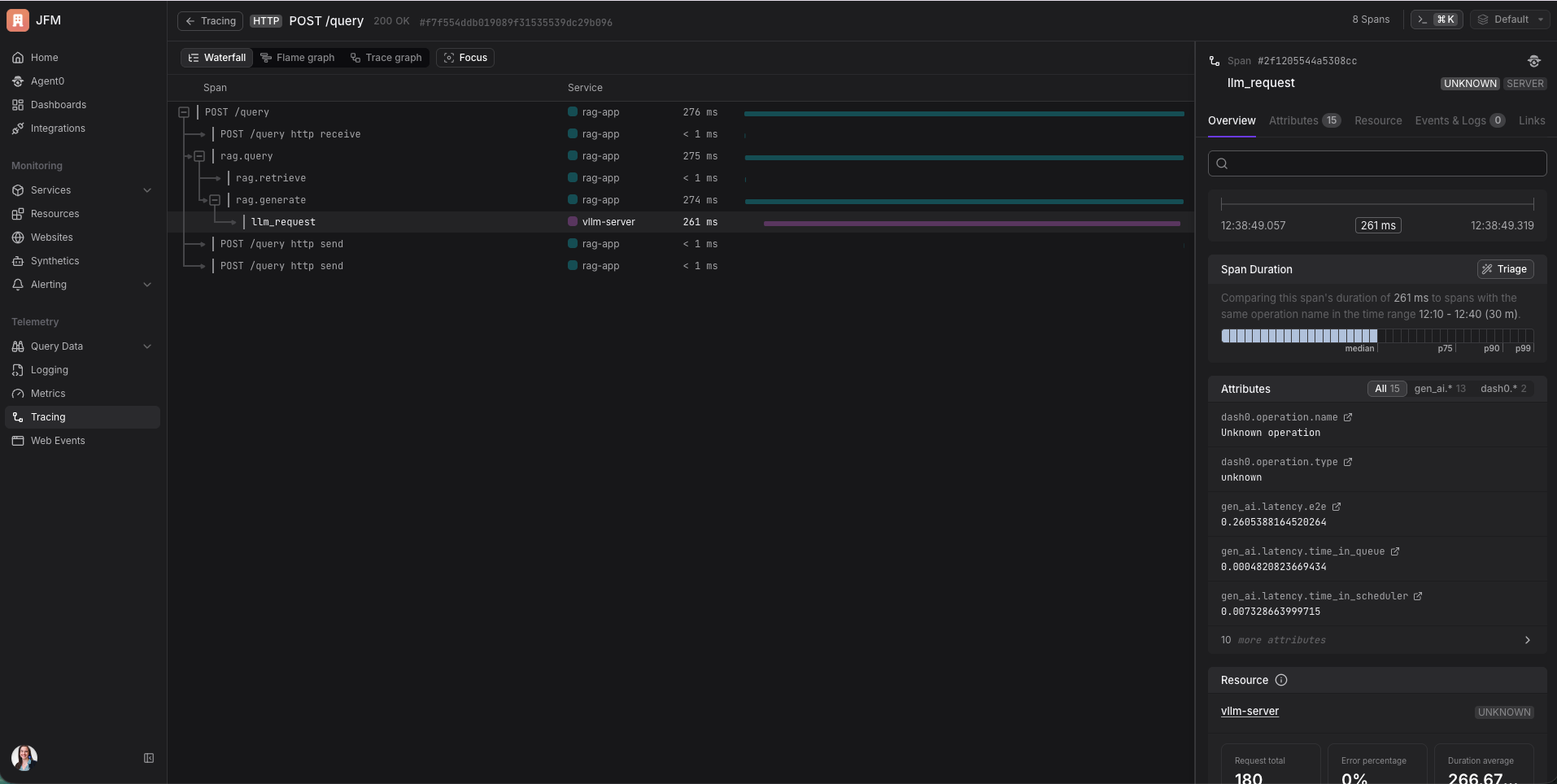
Une trace capture tout ça et te montre exactement où le temps est passé. L’IA était-elle lente parce que le serveur était débordé par d’autres requêtes ? Était-elle lente parce que le prompt était très long ? La trace te le dit.
Si tu le configures correctement, tu obtiens une trace continue qui traverse plusieurs services. Mon app RAG et le serveur vLLM sont deux processus séparés, mais dans Dash0 je les vois comme un waterfall connecté. “Mon app a mis 85ms à chercher des documents et 360ms à attendre l’IA.” En une seule vue. Sans aucune plomberie supplémentaire au-delà de l’injection d’un header. C’est beau à voir.
Les métriques : le tableau de bord sur le mur de ta cuisine 🔗
Les métriques sont des chiffres qui se mettent à jour dans le temps. Moins de détails que les traces, mais plus faciles à surveiller en continu et pour lesquelles créer des alertes.
Celles qui comptent vraiment:
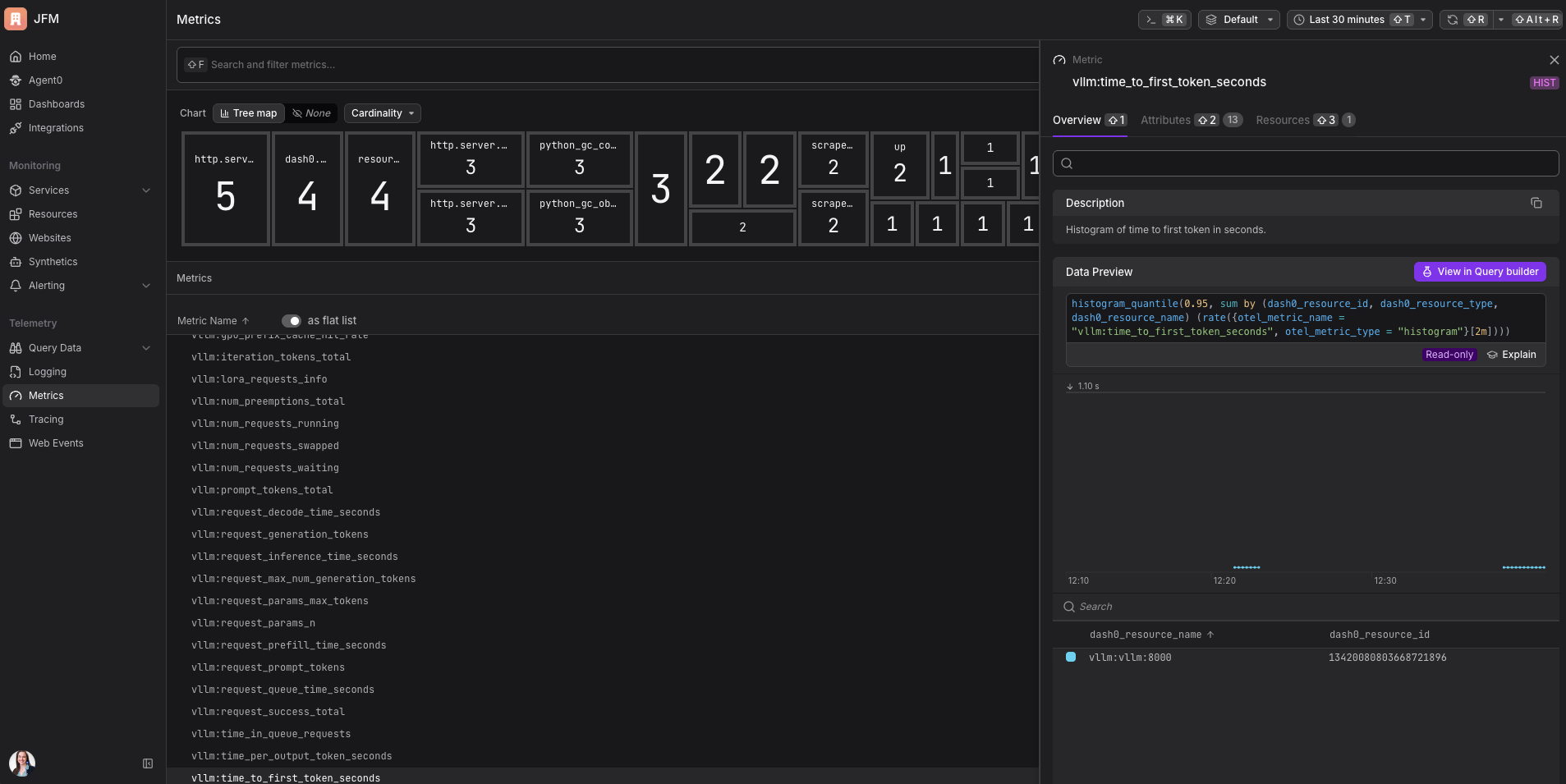
Temps jusqu’au premier token. Combien de temps avant que l’utilisateur voie le premier mot de la réponse. Pour tout ce qui a une UI de streaming où le texte apparaît au fil de la génération, c’est ce qui détermine si le produit se sent rapide. Je n’avais aucune idée que ça se mesurait séparément de la latence totale avant de creuser dans vLLM. Ça a tellement de sens rétrospectivement.
Utilisation du cache GPU. Celui-là a besoin de sa propre analogie. Le GPU dispose d’un type spécial de mémoire de travail appelé KV cache. Pense-y comme le carnet de notes d’un chef : quand le chef est au milieu d’une recette complexe, il prend des notes pour ne pas perdre le fil. L’IA fait la même chose pendant la génération. Quand le carnet est plein, le chef doit effacer les notes de quelqu’un d’autre pour faire de la place, ce qui signifie que la commande de cette personne doit repartir de zéro. Dans vLLM ça s’appelle une preemption, et ça cause des pics de latence soudains qui apparaissent comme des requêtes lentes plutôt que comme des erreurs. La métrique d’utilisation du cache GPU te dit à quel point ce carnet est plein avant que les choses commencent à s’effacer. Je n’aurais jamais pensé à surveiller cette métrique avant ce projet. C’est maintenant la première chose que je vérifie.
Requêtes en attente. Combien de requêtes sont en queue mais pas encore en cours de traitement. Ça monte avant que la latence explose. C’est un indicateur avancé, exactement le type de signal qui est utile pour la planification de capacité.
Tokens par seconde. Le débit de ton setup. Utile pour savoir si tu tires parti de ton matériel.
Comment les données circulent 🔗
Voici l’architecture en termes simples:
Ton app
│
│ envoie une question
▼
vLLM (le serveur IA)
│
├── envoie les données de traces automatiquement → OTel Collector
└── expose les métriques sur /metrics → OTel Collector les scrape
│
│ transfère tout
▼
Dash0
(où tu vois tout)
L’OTel Collector est un intermédiaire qui reçoit des données de plusieurs sources et les transfère vers ton backend d’observabilité. Pense-y comme la salle du courrier d’un immeuble : tout passe par là avant d’arriver à sa destination finale. Il gère aussi des choses comme le batching, les retries et l’enrichissement de la télémétrie avec du contexte supplémentaire, c’est pourquoi tu veux l’avoir dans le pipeline plutôt que d’envoyer directement.
OpenTelemetry (OTel) est le format standard que tout ça utilise. C’est vendor-neutral, ce qui signifie que le même setup fonctionne que tu envoies vers Dash0, Grafana, ou n’importe quel autre outil qui parle OTel. J’utilise Dash0 parce que c’est là où je travaille, lol. Voir les métriques et traces de vLLM apparaître dans la même vue sans écrire de code de colle, c’était le moment où tout a vraiment fait sens pour moi. Si tu es curieux·se de savoir pourquoi être OTel-native est important, ce post l’explique bien.
Comment le configurer 🔗
Le setup complet est dans le dépôt dash0-examples.
Ce qu’il te faut :
- Docker et Docker Compose
- Une machine avec un GPU NVIDIA
- Un compte Dash0 (basé sur la consommation, gratuit pendant 14 jours)
Le truc avec le GPU. Ça m’a bien eue. J’avais assumé que je pouvais juste lancer la démo en local sur mon Mac, peut-être lentement. Que nenni. L’image Docker de vLLM est compilée spécifiquement pour NVIDIA CUDA. Ce n’est pas une situation “tourne plus lentement sans GPU”, ça ne tourne tout simplement pas. J’ai passé un temps embarrassant à essayer de le faire fonctionner avant d’accepter la réalité et de lancer une instance Google Cloud.
Pour les tests j’ai utilisé une n1-standard-4 avec un GPU T4 sur Google Cloud (environ $0.50/heure). Plus que suffisante pour le petit modèle de cette démo. Un truc à vérifier avant d’essayer: Google Cloud limite par défaut le nombre de GPUs que tu peux utiliser, parfois à zéro. Va dans IAM & Admin → Quotas dans la console Google Cloud, cherche NVIDIA_T4_GPUS, sélectionne ta région et fais une demande d’augmentation. Elle est généralement approuvée en quelques heures. Je ne savais pas que ça existait jusqu’à ce que je me heurte à la limite et que je reçoive une erreur cryptique au lieu d’un message utile.
L’avantage de Google Cloud: tu peux te connecter à ton instance avec gcloud compute ssh plutôt que de gérer des fichiers .pem. Plus de chmod 400, plus de “où j’ai mis cette clé ?” :
gcloud compute ssh nom-de-ton-instance --zone=us-central1-a
Et une fois que tu as fini, pense à arrêter l’instance !! Sinon tu auras une facture énorme à la fin du mois.
L’attente au chargement du modèle. La première fois que tu lances docker compose up, vLLM télécharge les poids du modèle et les charge dans la mémoire GPU. Ça prend 2 à 5 minutes. Le stack a l’air figé. Il ne l’est pas. Attends cette ligne avant d’envoyer des requêtes :
INFO: Application startup complete.
J’ai envoyé des requêtes avant de voir cette ligne lors de ma première tentative. Je ne comprenais vraiment pas pourquoi rien ne fonctionnait. Maintenant tu le sais.
Étapes :
-
Clone le dépôt:
git clone https://github.com/dash0hq/dash0-examples.git cd dash0-examples/vllm -
Ajoute tes identifiants Dash0 dans le fichier
.envà la racine du dépôt. Tu peux les trouver dans la page de paramètres de ton compte.DASH0_AUTH_TOKEN=ton_token_ici DASH0_DATASET=default DASH0_ENDPOINT_OTLP_GRPC_HOSTNAME=ingress.us-west-2.aws.dash0.com DASH0_ENDPOINT_OTLP_GRPC_PORT=4317 -
Lance tout (nécessite un GPU NVIDIA, ou consulte la section de configuration vLLM dans l'analyse technique détaillée pour savoir comment le faire tourner sur CPU) :
docker compose up --build -
Attends que le modèle charge. Cherche
Application startup complete.dans les logs. -
Envoie une requête de test:
python scripts/send-request.py
Ensuite va sur Dash0. Les données devraient affluer.
Ce que tu vois concrètement 🔗
C’est la partie qui a fait que tout ça en valait la peine.
Dans les traces, chaque requête apparaît comme un arbre connecté. Tu peux voir le flux complet depuis la réception de la requête par ton app jusqu’à la fin de la génération par l’IA, avec le timing à chaque étape. Le span de l’IA a des attributs montrant combien de tokens étaient dans le prompt, combien ont été générés, et comment la latence se répartit à l’intérieur de vLLM (temps d’attente en queue, temps en prefill, temps en decode).
Dans les métriques, tu obtiens une vue en temps réel de la santé du serveur IA. Le cache GPU est-il en train de se remplir ? Une queue est-elle en train de se former ? La métrique sur laquelle je mettrais une alerte en premier : le temps jusqu’au premier token au 95e percentile. Si ça monte, les utilisateurs le ressentent avant que quoi que ce soit d’autre casse.
Pourquoi ça compte au-delà de la démo 🔗
C’est ce à quoi je n’arrêtais pas de penser dans l’avion du retour de Google Cloud Next.
Les agents que tout le monde démo ne sont pas des modèles uniques. Ce sont des pipelines avec un orchestrateur qui appelle des outils, récupère des données, lance des sous-agents, appelle un modèle, traite le résultat, rappelle le modèle. Chaque étape peut échouer. Chaque étape a de la latence. Sans instrumentation tu debuggues ce système complètement à l’aveugle.
Mais si chaque composant propage le contexte de trace à travers ses appels, et si la couche IA émet ses propres spans, tu te retrouves avec une trace continue par interaction utilisateur qui couvre toute l’exécution. Tu peux voir où le temps est passé, quels appels d’outils étaient lents, et si le goulot d’étranglement était le modèle ou l’infrastructure qui l’entoure.
C’est ce que je voulais pouvoir faire. Cette démo est la première étape. Beaucoup de gens dans la communauté cloud-native travaillent sur ce problème en ce moment même. Je n’ai pas encore toutes les réponses, mais je pense que construire et partager au fur et à mesure, c’est comme ça qu’on va le résoudre ensemble.
Si tu veux voir à quoi ressemble l’observabilité agentique une fois que l’infrastructure est en place, Dash0 a un guide pratique qui vaut la peine d’être lu en parallèle de ce post.
Essaie toi-même 🔗
L’exemple complet est sur dash0-examples/vllm. Clone-le, pointe-le vers ton modèle, et vois ta couche d’inférence devenir observable en quelques minutes. Commence ton essai gratuit Dash0 si tu n’as pas encore de compte.
Si tu essaies et que quelque chose n’est pas clair, retrouve-moi sur LinkedIn. Et si tu penses déjà à comment étendre ça à des pipelines d’agents complets, moi aussi. C’est ce sur quoi je travaille ensuite. 💙